New DNA data reveals the origins of the Slavic peoples
Also this week: How our DNA holds the history of our language + The Cambridge dictionary adds 6,000 new words—and not everybody’s happy about it. Here’s what happened this week in language and linguistics.

Welcome to this week’s edition of Discovery Dispatch, a weekly roundup of the latest language-related news, research in linguistics, interesting reads from the week, and newest books and other media dealing with language and linguistics!
📢 Updates
Announcements and what’s new with me and Linguistic Discovery.

Every week the Green Mill Cocktail Lounge in Chicago—one of the oldest bars in the city (tracing back to the 1890s!!) and one of the most famous bars in the United States—hosts a weekly live show with an awesome lineup of talented musicians and stand-up comedians, including the hilarious (and extremely tipsy) Chad the Bird (pictured below).

Despite being situated a mere two blocks from my apartment, I’d never gotten to patronize the Green Mill until this last weekend, when by sheer luck Chad the Bird had prepared an amazing bit about etymology and the 6,000 new words that were just added to the Cambridge dictionary. I could barely contain both my joy and laughter, so I had to share Chad the Bird’s bit with you all as well:
🆕 New from Linguistic Discovery
This week’s content from Linguistic Discovery.
🎃 Pumpkin Spice Linguistics
Starbucks has officially kicked off pumpkin spice latte season, which means it’s time for some Pumpkin Spice Linguistics!
Did you know that the word pumpkin was most likely borrowed from the Massachusett language by the Plymouth colonists? And that the word spice originally comes from a verb meaning ‘to observe’?
In this 20-minute talk given at the Edmonton Nerd Nite in 2022, I discuss the winding history of these two words and what they can teach us about both language change and indigenous history:
📰 In the News
Language and linguistics in the news.
6,000 new words added to the Cambridge dictionary—and not everybody’s happy about it

The Cambridge dictionary added 6,000 new words to the dictionary this month, including many recent Gen Z neologisms such as skibidi, tradwife, broligarchy, and delulu. It’s important to remember that lexicographers don’t just add any old fads to the dictionary either. Only words that lexicography researchers believe are likely to stick around get added, although inevitably many will eventually drop out of use and later become marked as archaic—a fate shared by probably the majority of new words in a language.



Paraguay is fighting to preserve Guarani
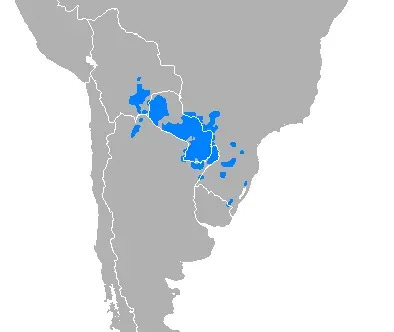
Paraguay is fighting to preserve Guarani as fluency slips among younger generations.
Guarani is a member of the Tupian language family, and is one of the most widely spoken Native American languages. About half the rural population of Paraguay are monolingual speakers of the language. One thing that makes standardization tricky is that Guarani is a dialect continuum.
However, fluency among younger generations is slipping. And one thing that makes standardization tricky is that Guarani is a dialect continuum.

🗞️ Current Linguistics
Recently published research in linguistics.
Genetic mixing correlates to language mixing
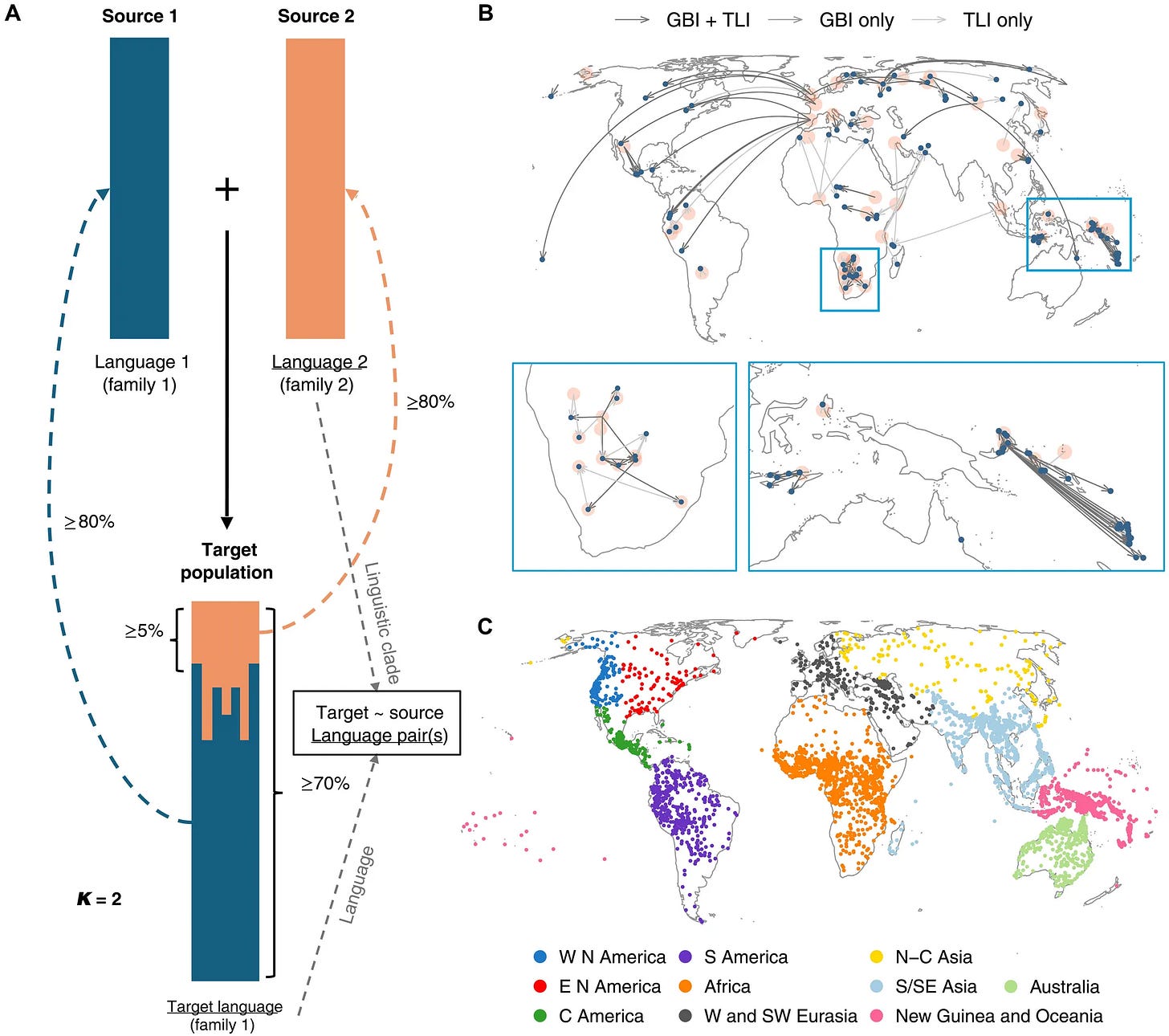
When speakers of different languages are in contact, they often borrow not just words, but also sounds and grammatical patterns from one another. However, most languages of the world are not well documented, and have little to no historical records, making it hard to know which similarities across languages are borrowed or merely coincidental. A new study published in Science Advances aims to estimate the degree of language contact in languages of the world by looking at the genetic histories of different populations instead. Using the AUTOTYP database for mapping linguistic features, the authors find that language pairs whose speaker populations underwent genetic admixture or that are located in the same geohistorical area exhibit higher incidences of shared linguistic patterns. However, the effect varies strongly depending on the specific linguistic feature. Their analysis also challenges previous research about the borrowability of certain features of language.
Reporting

Original Research
- Graff et al. 2025. Patterns of genetic admixture reveal similar rates of borrowing across diverse scenarios of language contact. Science Advances 11(35). DOI: https://doi.org/10.1126/sciadv.adv7521.
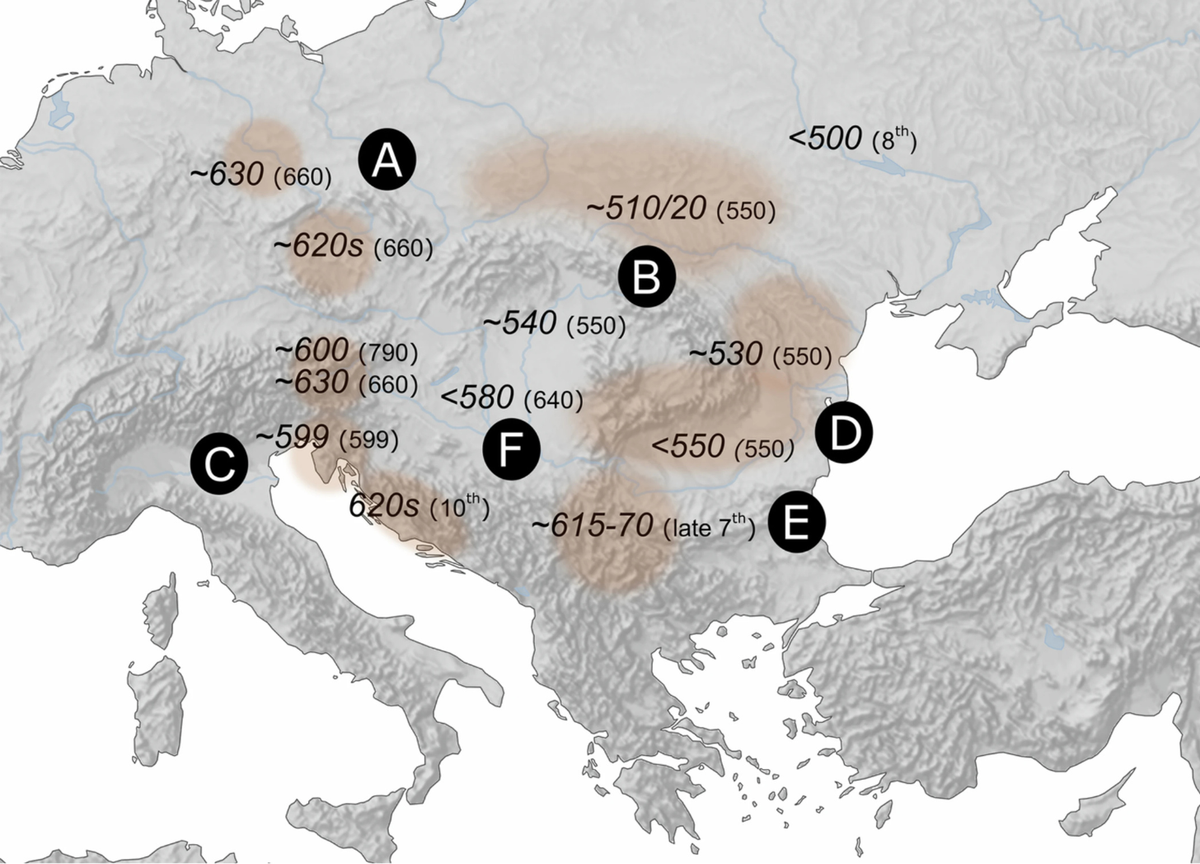
The genes of ancient skeletons reveal the origin of the Slavic people

A new study published in Nature uses DNA evidence to connect the modern Slavic people to a wave of migration following the fall of the Roman Empire.
Today, Slavic languages are spoken from the beaches of the Baltic Sea to Russia’s Pacific coastline. But where the Slavs came from—and how their languages spread out across thousands of kilometers in Eurasia—has long perplexed scholars. Did a small number of Slavic-speaking elites impose their languages and cultures on existing populations? Or did Slavs move in from the east, replacing the previous inhabitants of what are now Poland, Germany, Bohemia, and the Balkans following the Roman Empire’s collapse?
A study of hundreds of ancient genomes published today in Nature backs the second scenario, suggesting Europe’s “Slavicization” process was linked to bands of Slavic speakers migrating west in large numbers.
- Ancient skeletons’ genes reveal origin of the Slavic people (Science)
- Gretzinger et al. 2025. Ancient DNA connects large-scale migration with the spread of Slavs. Nature. DOI: https://doi.org/10.1038/s41586-025-09437-6.
📃 This Week’s Reads
Interesting articles I’ve come across this week.
- Why Brits add an /r/ to words that end in vowels (but only sometimes) (Upworthy)
- Why do we say “um” so much? It’s not just a meaningless filler like you might think! (NPR)

- English is not very representative of what the world’s 7,000 languages are like, yet the majority of research in linguistics focuses on English.


📚 Books & Media
New (and old) books and media touching on language and linguistics.
A really short history of words

Many linguaphiles are already familiar with Bill Bryson’s wonderful book Mother tongue: English and how it got that way. Now Bill Bryson has published an illustrated accompaniment to that book, but written for kids!
🗃️ Resources
Maps, databases, lists, etc. on language and linguistics.
The Indo-European Lexicon
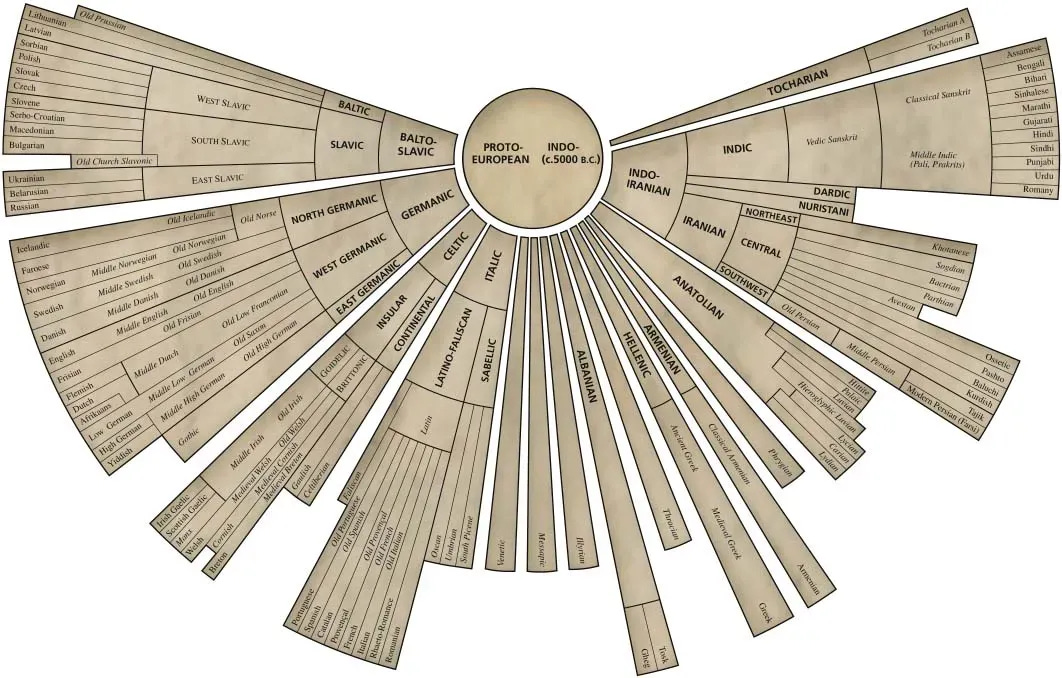
The Linguistics Research Center at the University of Texas at Austin hosts the fantastic Indo-European Lexicon, a database of the words and affixes of Proto-Indo-European compiled by Jonathan Slocum. Each entry also shows all the descendants (reflexes) of the word in any of the modern languages that still have it.

❓ How do you like your Linguistic Discovery articles?
I like writing long deep-dives. It’s a great way for me to collect everything about a topic in one place, which people can come back to and reference whenever they’d like. I’m also pretty sure y’all enjoy reading these more immersive longform articles (but please reply to this and let me know if this is true!).
I’ve usually posted these longer features as a single lengthy article, like so:
2,500 words:

3,500 words:

3,500 words:

6,000 words:
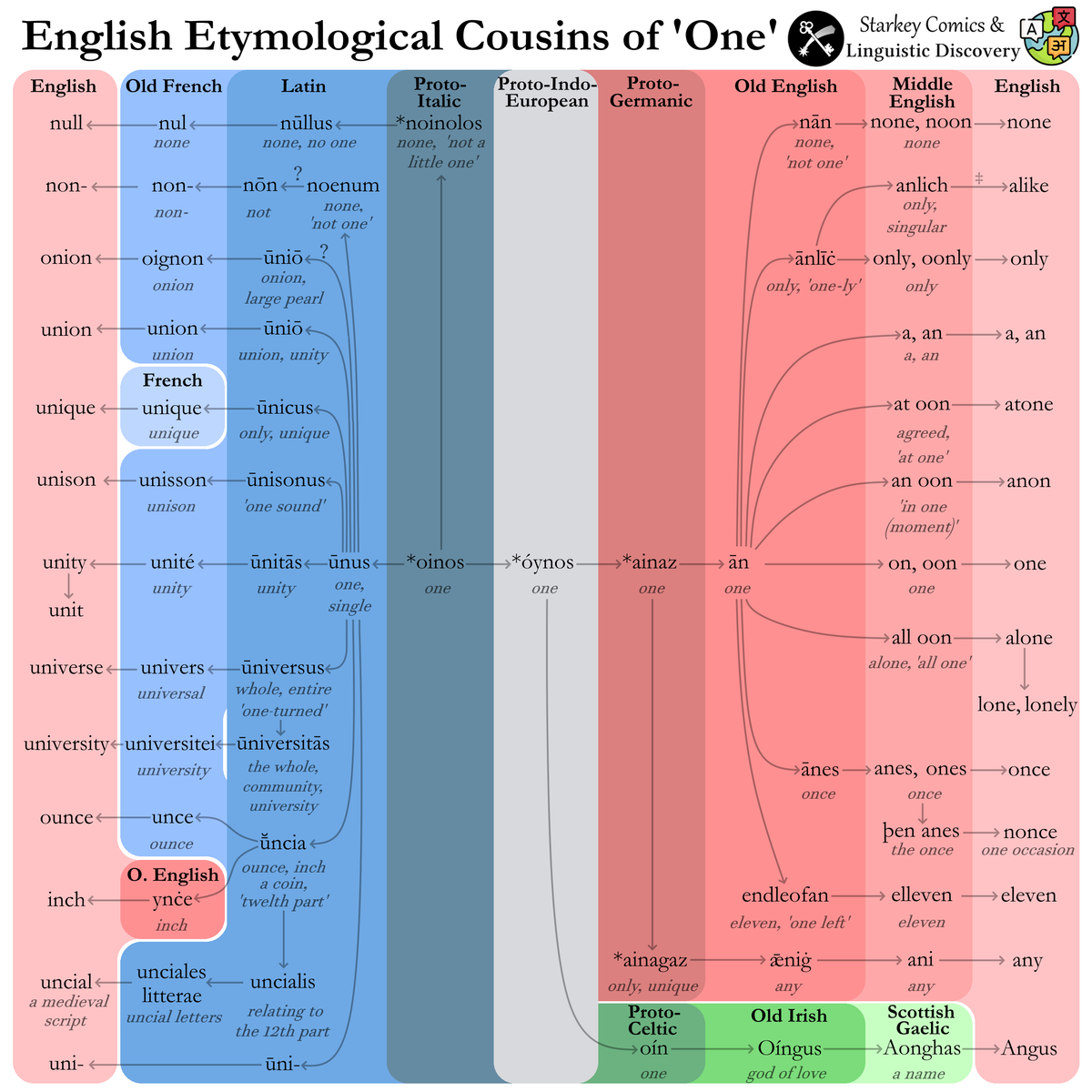
But recently I tried syndicating a long piece as a 4-part series, in my review of the linguistics of The Iron Dreamers:




If I had published this series as a single article, it would have been 15,000 words! Similarly, I’m working on a long piece right now that will likely reach about 10,000 words.
My question for you is this: Would you rather read longform pieces like these as a single essay, published less frequently, or have them broken up into parts and delivered a week apart? Let me know in the poll below. Thanks!
If you’d like to support Linguistic Discovery, purchasing through these links is a great way to do so! I greatly appreciate your support!
Check out my entire Amazon storefront here.