Your cryptogram is lying to you—/t/ isn’t the most frequent consonant in English
What are the most frequent sounds across languages (and why)?


If you’ve spent much time solving cryptograms, you probably already know that ⟨t⟩ is the most frequently used consonant in written English. Given that, it’s reasonable to assume that /t/ would be the most frequent sound in English too.
So imagine my surprise earlier this week when, as I was reading the latest issue of Babel: The Language Magazine, I learned that the most frequent consonant in spoken English isn’t /t/ at all—it’s /n/!
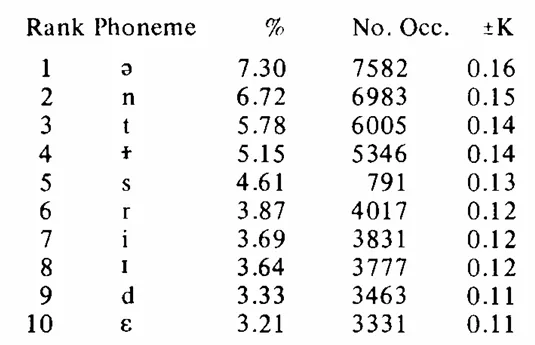
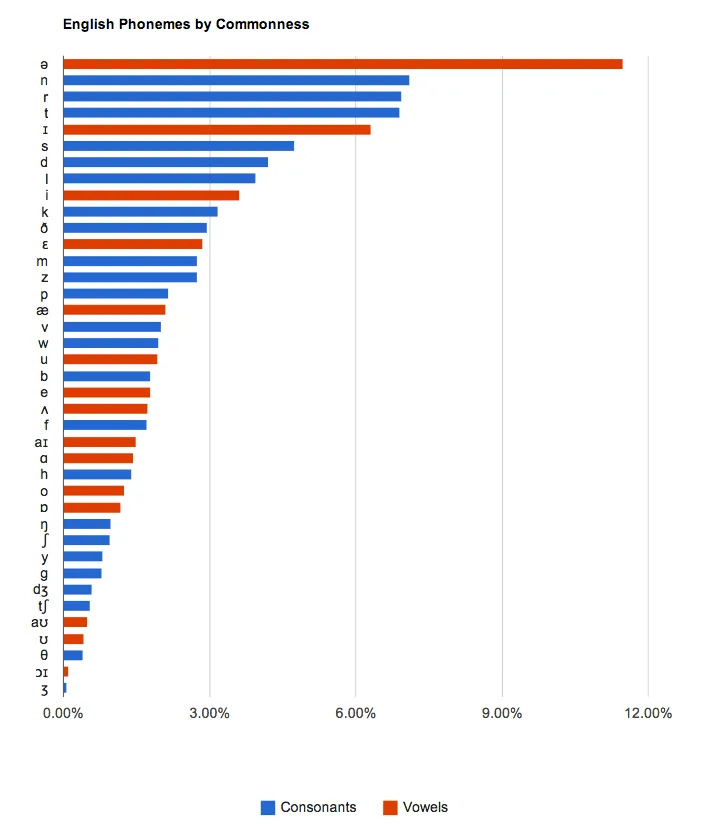
In linguistics, ⟨angle brackets⟩ refer to the written (orthographic) representation of a word or letter, while /slashes/ refer to the spoken (phonemic) representation of a word or sound. For example, the word house is written as ⟨house⟩ but pronounced as /haʊs/ in most dialects of American English. You can learn more about how to read linguistics on this page.
What’s going on here? Why the discrepancy?
The fact that the relative frequency of ⟨t⟩ and /t/ differ immediately tells us something interesting: either a) many of the written ⟨t⟩s in English are not pronounced as /t/ (or are silent), or b) in speech we use more words with /n/ and fewer words with /t/ than we do in writing. So which is it?
There’s good reason to suspect the former. The most frequent words from the Oxford English Corpus (OEC) and Corpus of Contemporary American English (COCA), are listed below. (These rankings are roughly the same for other dialects of English too.)
| Word | OEC Rank | COCA Rank |
|---|---|---|
| the | 1 | 1 |
| be | 2 | 2 |
| to | 3 | 6 |
| of | 4 | 5 |
| and | 5 | 3 |
| a | 6 | 4 |
| in | 7 | 7 |
| that | 8 | 13 |
| have | 9 | 11 |
| I | 10 | 8 |
| you | 18 | 9 |
| it | 11 | 10 |
Here’s a graph of the COCA frequencies, per million words:
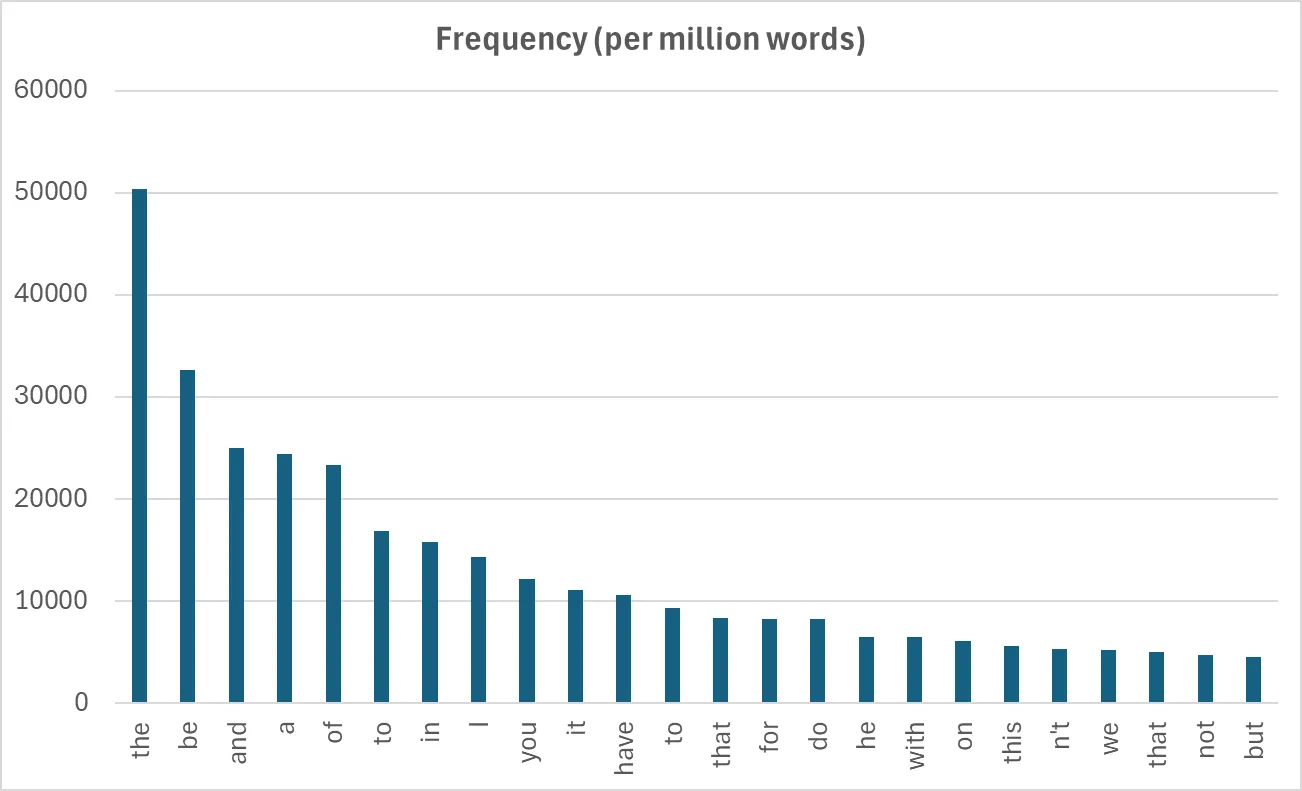
The word the appears drastically more often than any other word, which explains why ⟨t⟩ is the most frequent consonant letter of English. However, the ⟨t⟩ in ⟨the⟩ isn’t pronounced as a /t/; as part of the two-letter combination (digraph) ⟨th⟩, it’s pronounced as a voiced dental fricative /ð/, which is a completely different consonant sound than /t/. Compare the following pairs of words that differ by only a single sound (called minimal pairs), /t/ vs. /ð/.
| Word with /t/ | Pronunciation | vs. | Word with /ð/ | Pronunciation |
|---|---|---|---|---|
| toe | /toʊ/ | though | /ðoʊ/ | |
| tear [separate or pull apart] | /tɛɹ/ | there, their | /ðɛɹ/ | |
| tea | /ti/ | the | /ði/ (before vowels) | |
| tan | /tæn/ | than | /ðæn/ | |
| ten | /tɛn/ | then | /ðɛn/ |
So while the letter ⟨t⟩ occurs more frequently than any other consonant by virtue of its appearance in the at rank 1, the sound /t/ doesn’t even make its appearance on the COCA frequency list until to at rank 6! By contrast, the /n/ sound appears in the word and at rank 3, as well as the word in at rank 7. And, on the COCA list, instances of a also include instances of an, so /n/ is used at rank 4 as well.
This discrepancy between the frequency of written ⟨t⟩ and spoken /t/ explains why their rankings differ in written vs. spoken English.
But the frequency of /n/ in English surprised me for another reason too: We know that there’s a strong correlation between the number of languages that have a sound and the frequency of that sound within individual languages (Gordon 2016: 74). The following chart demonstrates this, showing the intralanguage vs. interlanguage frequency of different consonants.
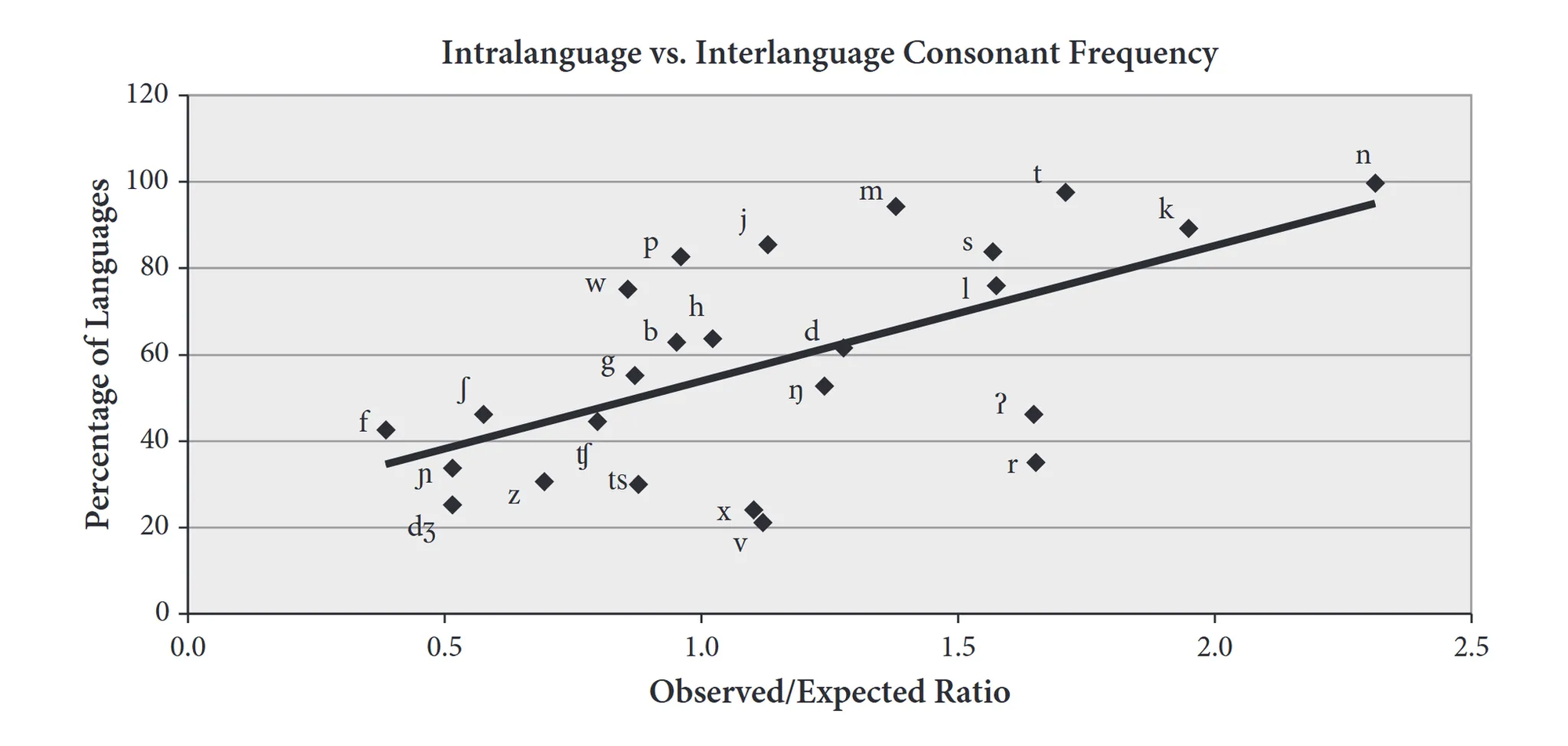
And I thought (incorrectly, it turns out) that the most common consonant sounds in the world’s languages were the voiceless stops /p, t, k/. Therefore, I reasoned, it would be unsurprising for /p, t, k/ to be the most frequent consonants within English as well.
Why did I think this? Because that’s what I’d been taught! One widely-used textbook on the sounds of the world’s languages, for example, says the following:
Some consonants occur more frequently than others. The most common are the voiceless stops. About 98 percent of the world’s languages have the three voiceless stops /p, t, k/, and every known language has sounds similar to two of these three. (Ladefoged & Disner 2012: 158)
It’s unclear to me where this claim comes from, and I’m not able to replicate that statistic using the well-known phonological databases UPSID or PHOIBLE. In reality, the most frequent consonant in the world’s languages is not actually /t/, but—you guessed it—/n/! It turns out that the frequency rank of /n/ in English actually does match its rank crosslinguistically, in line with the pattern we saw above. And while /p, t, k/ are among the most frequent consonants crosslinguistically, they compete with /m/, /j/, and /s/, as the following chart shows.
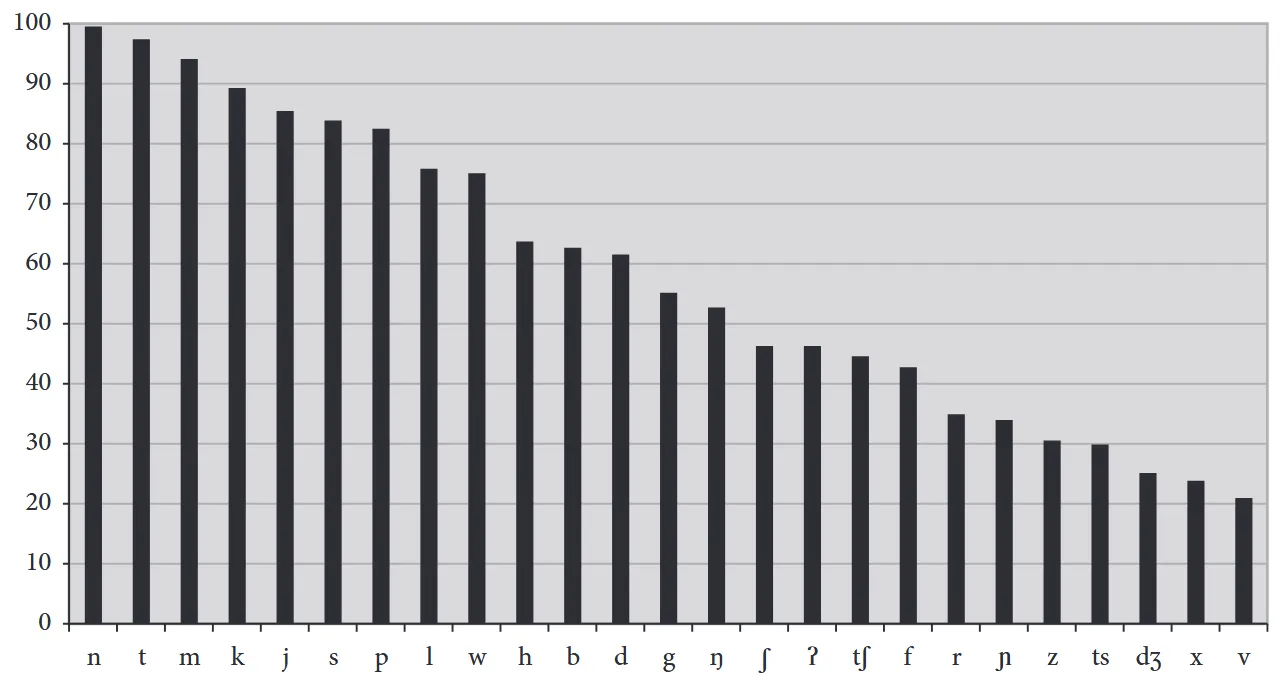
Why do many linguists think that voiceless stops are the most common consonants in the world’s languages? I believe we were misled by the idea that some sounds are more “default” than others, either by virtue of being easier to pronounce, or being acquired earlier in the language learning process, or by being the sound that appears in the absence of any other conditioning factors. For example, the plural suffix -s in English actually has three different pronunciations depending on the sound that comes before it:
| Pronunciation | Conditioning Factor | Example |
|---|---|---|
| [ɪz] | after sibilants /s, z, ʃ, ʒ, tʃ, dʒ/ | house → houses [haʊs] → [haʊzɪz] |
| [z] | after voiced sounds: vowels, /b, d, g, m, …/ | home → homes [hoʊm] → [hoʊmz] |
| [s] | everywhere else | cat → cats [kæt] → [kæts] |
The last of these is the “elsewhere condition”, i.e., the default realization of this sound. Since that pronunciation is used in a much larger set of contexts than the other pronunciations, it’s the most frequent pronunciation. Linguists call this the unmarked pronunciation. For plural -s, [z] is a marked pronunciation in comparison to [s].
Now look at the crosslinguistic frequencies of /s/ and /z/ in the chart above. Notice that /s/ is substantially more frequent in the world’s languages than /z/. This is partially a reflection of the fact that /s/ is more likely to be the default pronunciation of sounds in the world’s languages than /z/ is, just like the English plural -s. Similarly, the sounds /p, t, k/ are typically considered the unmarked option when compared to other consonants (Haspelmath 2006: 28). So it seems reasonable to assume that /p, t, k/ would be the most frequent consonant sounds in the world’s languages too.
The problem with this way of thinking is that it has the direction of causation backwards. Markedness is just an observed pattern of asymmetries between different sounds in the world’s languages. It’s a description, not an explanation. It’s the patterns of markedness themselves that need explaining, and those patterns are better explained by factors like ease of articulation, distribution, or conditioning factors than some vague notion of “defaultness” (Haspelmath 2006). Even though /p, t, k/ are usually the unmarked option in any given comparison, there are plenty of other factors which contribute to the frequencies of different sounds within languages, and that is why /p, t, k/ are less frequent than other, more marked sounds like /n, m, j/.
Interestingly, /t/ is the most common consonant sound in English in terms of how many dictionary words and their various forms (i.e. how many lexemes) it appears in, as the graph below shows. But since some dictionary words are used much more often in speech than others (like the), the frequencies of different sounds are biased towards the sounds in those more commonly used words.
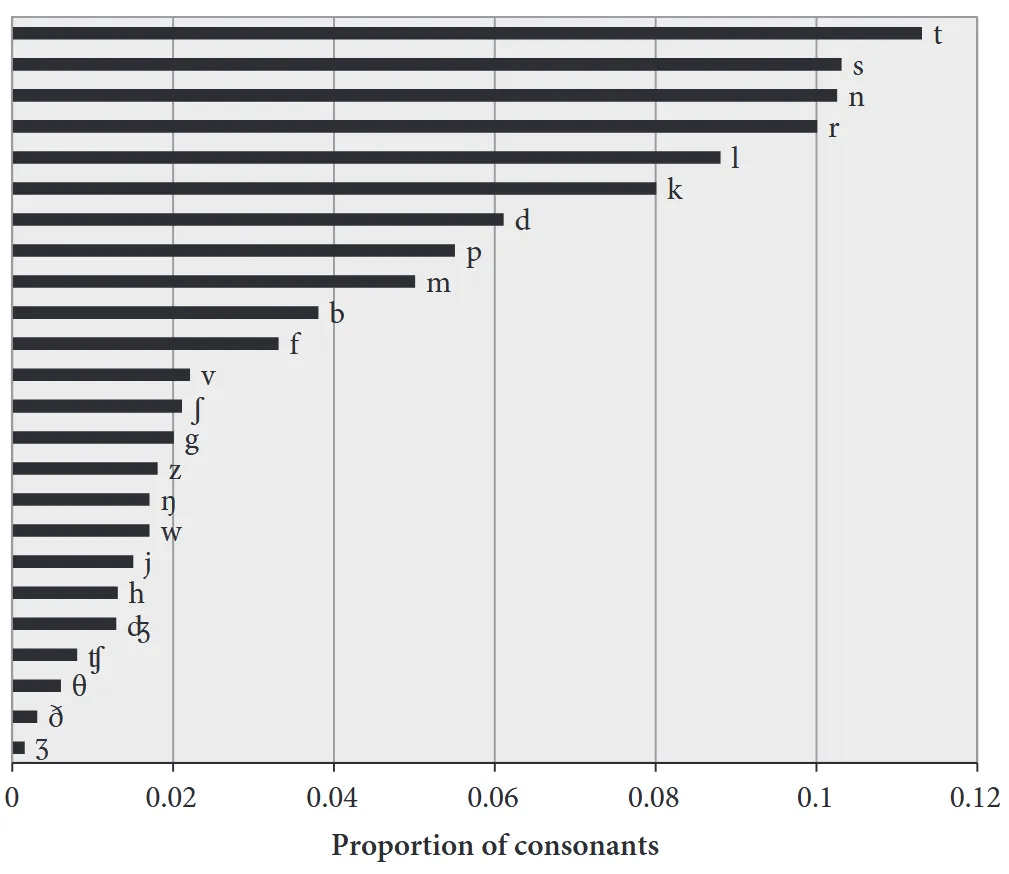
This hasn’t always been the case in English, though. In Old English, the most common consonant sound when measured by dictionary words was /n/! (Are you starting to see the pattern here?) The following chart compares the dictionary frequencies of consonants in Old English vs. Modern English.
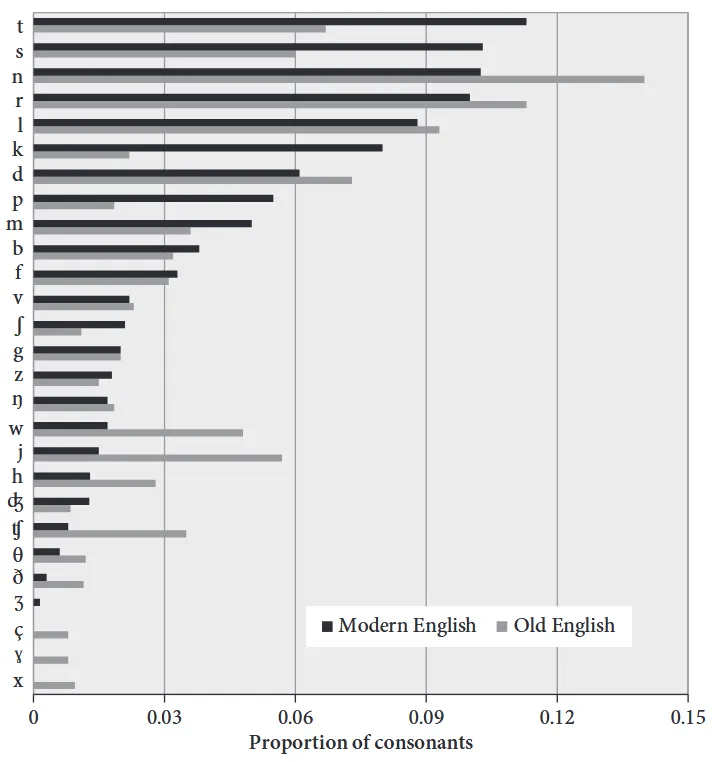
In Old English, /n/ was not only the most frequent consonant in spoken speech (presumably), but also occurred in more words than any other consonant. The frequency of Old English sounds more closely matched the frequency of Old English letters because English spelling was still largely “phonetic” at that point. For the most part there was a one-to-one correspondence between letters and phonemes (distinctive sounds in a language). It wasn’t until the Great Vowel Shift and the era of the printing press (c. 1400s–1600s) that English pronunciation diverged drastically from its written form.
In conclusion, your cryptograms have probably tricked you into thinking that /t/ is more frequent than it actually is in English.
Wouldn’t it be cool if there were a version of cryptograms (or Wordle!) that used the International Phonetic Alphabet instead of English spelling? Well guess what—there is! For Wordle at least:
Thank you so much for your support!
🙏 Credits
This issue of the Linguistic Discovery newsletter was edited by Amy Treber. If you’re looking for professional copyediting services, email Amy at amytreberedits@gmail.com.
The final responsibility for any mistakes or omissions is of course still wholly my own.
📚 Recommended Reading

📑 References
- Blumeyer, Doug. 2012. Relative frequencies of English phonemes. Cmloegcmluin. https://cmloegcmluin.wordpress.com/2012/11/10/relative-frequencies-of-english-phonemes/.
- Davies, Mark. 2008–present. The Corpus of Contemporary American English (COCA). Available online at https://www.english-corpora.org/coca/.
- Mines, M. Ardussi, Barbara F. Hanson, & June E. Shoup. 1978. Frequency of occurrence of phonemes in conversational English. Language & Speech 21(3): 221–241. DOI: https://doi.org/10.1177/002383097802100302.
- Oxford Dictionaries Online. 2012. The Oxford English Corpus. Available online at https://www.sketchengine.eu/oxford-english-corpus/.
If you’d like to support Linguistic Discovery, purchasing through these links is a great way to do so! I greatly appreciate your support!
Check out my entire Amazon storefront here.



