How did the Indo-Europeans spread?
Also this week: What does conversation look like in the brain? Here’s what happened this week in language and linguistics.

Welcome to this week’s edition of Discovery Dispatch, a weekly roundup of the latest language-related news, research in linguistics, interesting reads from the week, and newest books and other media dealing with language and linguistics.
I had the great pleasure of getting to work with The Humane Space last year to put together a week’s worth of lessons on linguistics (which you can see here!), and I love the philosophy with which they approach their lessons. They aim to inject a little wonder and curiosity into your every day, which is exactly what I try to do with Linguistic Discovery. Their lessons cover a huge range of topics, from linguistics to weaving to gardening to the Norse goddess of winter Skaði. Every day is a little intellectual adventure.
If you’re interested in trying out The Humane Space, you can get a free month subscription to the app at the link:

🆕 New from Linguistic Discovery
This week's content from Linguistic Discovery.
Linguistic Idiocentrism
I love how people immediately leap from “I’ve never heard that” to “nobody says that” or “that’s just wrong” https://t.co/gs0497aik2
— Linguistic Discovery (@lingdiscovery) March 22, 2025
Whenever I mention any sort of dialect diversity in English (words, phrases, or pronunciations that are particular to specific dialects) on social media, I inevitably receive comments along the lines of “nobody says that” or “that’s incorrect”, rather than simply, “I’ve never encountered that. That’s different from how I talk.” Seeing this so often on social media reminds me of the False Consensus Fallacy:
a pervasive cognitive bias that causes people to “see their own behavioral choices and judgments as relatively common and appropriate to existing circumstances”. (Wikipedia: False consensus effect)
You might call the linguistic version of this Idiolectal Bias or maybe Linguistic Idiocentrism—the belief that your particular way of speaking is in some way more common, standard, or correct. This is why most people think they don’t speak with an accent. The reality is, however, we don’t have as much exposure to other ways of speaking as we think; and even when we do encounter such variation, we’re really bad at noticing it. I linked to a study a few weeks ago that showed just how bad, in fact:

So the next time you encounter a way of speaking you’ve never heard before, consider the strong likelihood that a lot more people say it that way than you realize!

📰 In the News
Language and linguistics in the news.
In response to Trump’s executive order declaring English the official language of the executive branch, the Linguistic Society of America (LSA) has issued a statement against it:
The LSA’s main points, backed by various studies which they cite, are:
- The United States has always been a multilingual country, and this gives it strength.
- Citizens of the US and of all democracies inevitably have different linguistic ways of navigating their lives, and enforced monolingualism never achieves national unity.
- “Official English” policies do not improve economic prospects for those who arrive in the US speaking another language, nor do they improve communication for those who live in multilingual communities.
- Supporting and promoting multilingualism makes a nation stronger, not weaker.
In a similar but more caustic vein, linguists Mark Turn and Ross Perlin (the latter of whom authored the bestselling book Language city: The fight to preserve endangered mother tongues in New York [Amazon | Bookshop]) wrote an article in The Conversation trenchantly attacking Trump’s order as reflecting the president’s own “linguistic insecurity, […] weakness, and fear”.

For my own take on Trump’s order, check out this issue of the newsletter:

🗞️ Current Linguistics
Recently published research in linguistics.
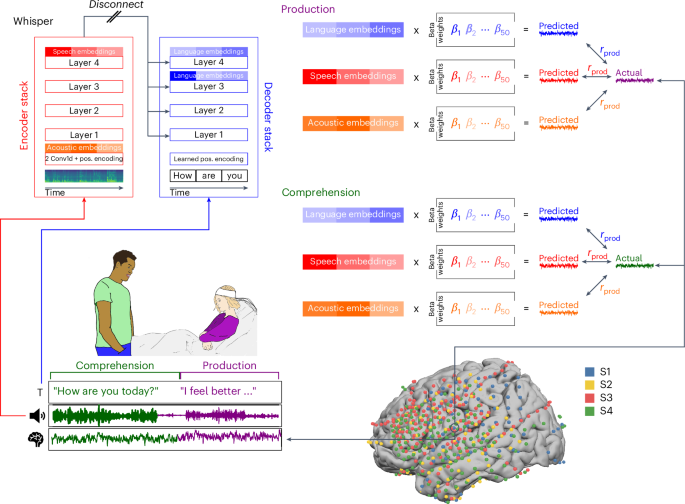
Predicting what conversation looks like in the brain
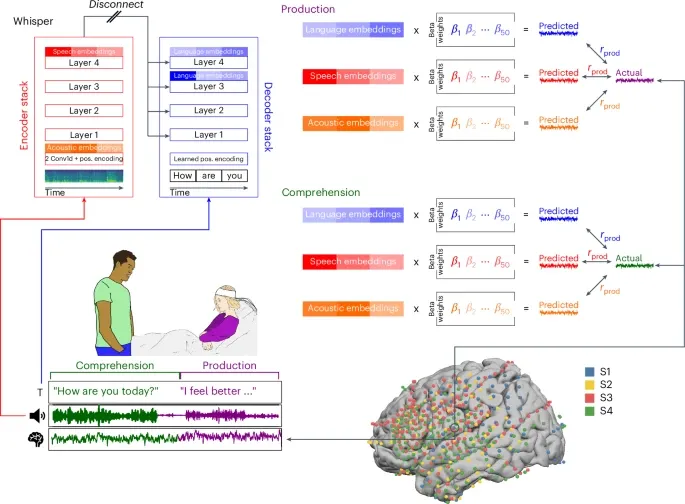
Researchers have long tried to map different aspects of speech onto activity in different regions of the brain. As you might expect, it’s nowhere near as straightforward as we’d like: saying the word “apple” doesn’t always light up the same areas of the brain in the same ways. Language is highly context-dependent. And speech is such a complex network of sounds and words and syntactic constructions and meanings that it’s impossible to cleanly map these various components of language onto brain activity. In the past, researchers have avoided this problem by focusing on just one aspect of speech at a time—prosody (like we looked at the other week), syntax, meaning, etc.
This study uses a speech recognition model called Whisper instead, which is designed to transcribe audio recordings of natural conversations. Whisper analyzes the speech stream at multiple levels, just like language itself—low-level acoustic information all the way up to high-level information about which words tend to appear in which contexts. The authors recorded about 100 hours of conversation while monitoring the brain activity of the speech participants using electrocorticography (ECoG)—a corpus of 520,209 words, which is incredibly large for an experiment measuring brain activity. Traditional experiments in this area involve participants reading a passage of text or just a few dozen sentences. So the scale of the data for this study is remarkable, enabling a much more accurate computational model of speech.
What the authors found is that the internal representations created by the Whisper language model mapped onto brain activity better than traditional computational models which don’t create these hierarchical internal representations. And they were able to watch speech production and processing happen in real-time. They could see, for example, that the brain progresses from thinking about what it wants to say, to beginning to form sounds. Then, after listening, the brain thinks back on what was just said.

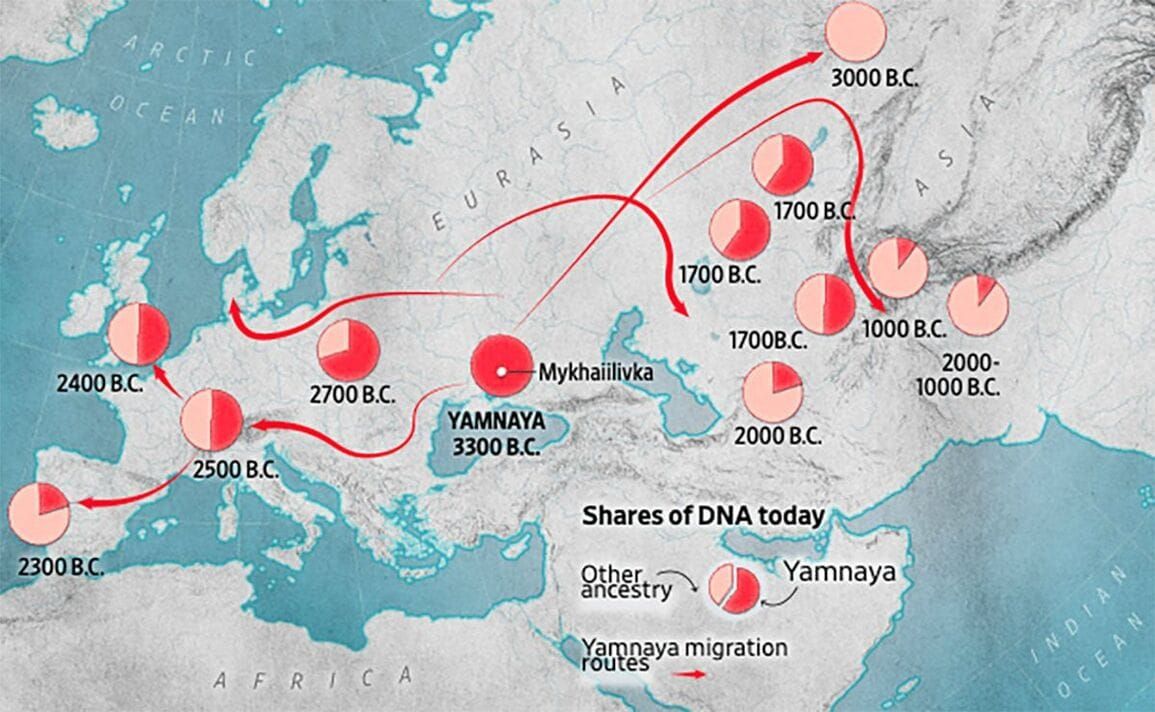
The genetic spread of the Indo-Europeans
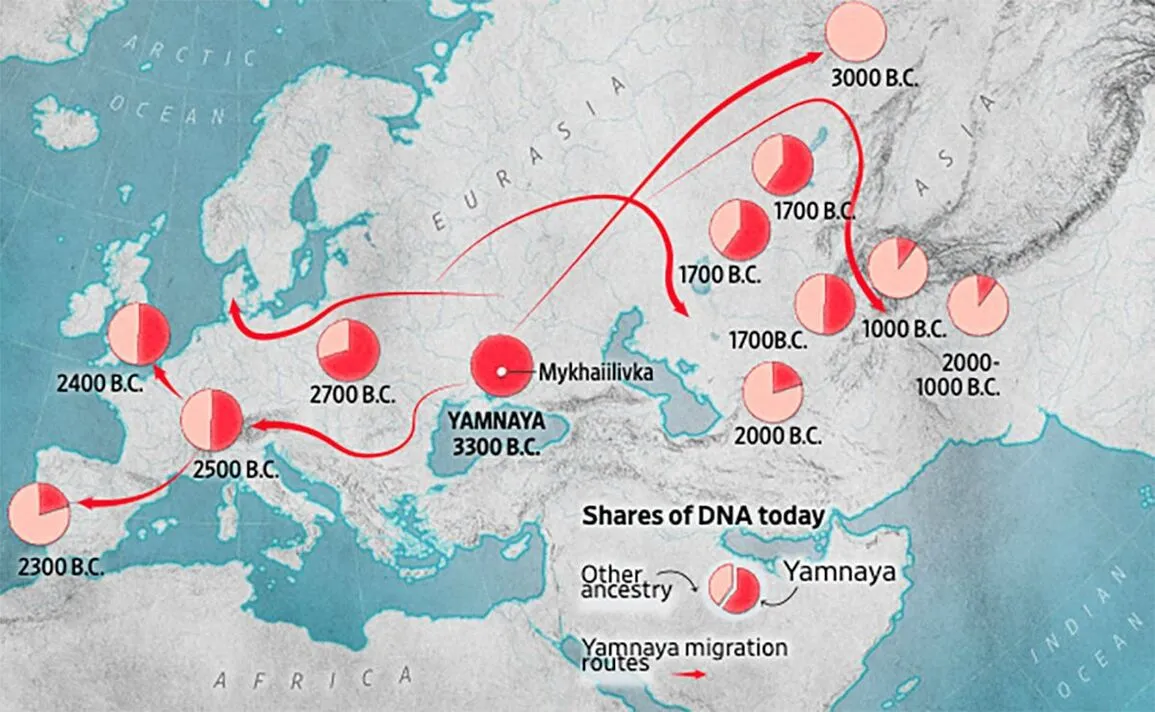
I reported last month that new DNA evidence helped further solidify our understanding of the origins of the Indo-European peoples and their language, called Proto-Indo-European. Current evidence tells a story where Pre-Indo-European peoples migrated from Anatolia to the Ukrainian steppe just north of the Black Sea sometime before 3000 BCE. They then mixed with the local people there, becoming a group that archaeologists call the Yamnaya.
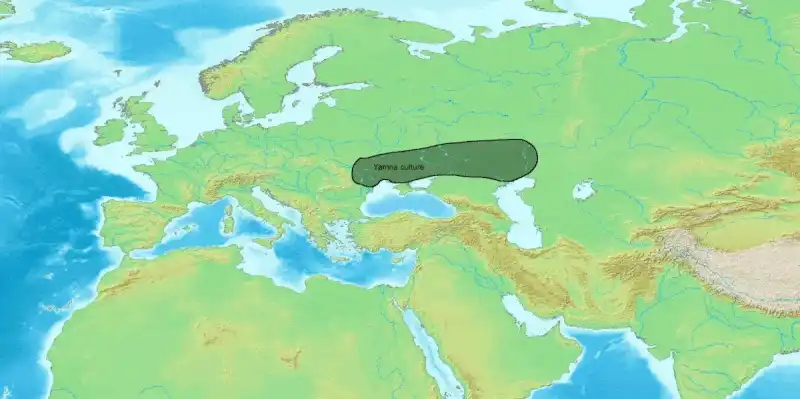
The Yamnaya would go on to have a profound impact on Eurasian history. They were likely the first people to ride horses and use wheeled carts, making them an unstoppable invading force for other cultures of Eurasia at the time. They spread rapidly across the Eurasian steppe and throughout Europe, bringing their languages with them and often killing the males of any society who resisted. As a result of this tidal wave of cultural replacement and the subsequent histories of their descendants, today about 42% of the world’s population speaks an Indo-European language.
While last month’s reporting on this research focused on its linguistic implications, this round of reporting is now drawing attention to the genetic implications: the descendants of the original Indo-Europeans can trace their ancestry to the Yamnaya of 5,000 years ago—and indeed to a single hamlet in the Russian-occupied region of Ukraine called Mykhailivka, an archaeological site spanning 3635–3383 BCE. The authors came to this conclusion by analyzing the DNA samples from 450 prehistoric individuals taken from 100 sites in Europe, as well as data from 1,000 samples that had been previously analyzed. The DNA of an individual from Mykhailivka is the crucial genetic link between the earlier peoples that migrated into the region and the later Yamnaya.
- Reporting: The ancient horsemen who created the modern world (WSJ)
- Non-paywalled version available at MSN here.
That’s it for this week! Thank you so much for being a subscriber, and I hope you enjoyed this issue! If you’d like to support Linguistic Discovery and help educate the world about the science and diversity of language, consider becoming a supporter! You’ll get bonus articles/videos and early access to chapters of my book!
Have a great week!
~ Danny
🚫 Errata
Corrections and clarifications.
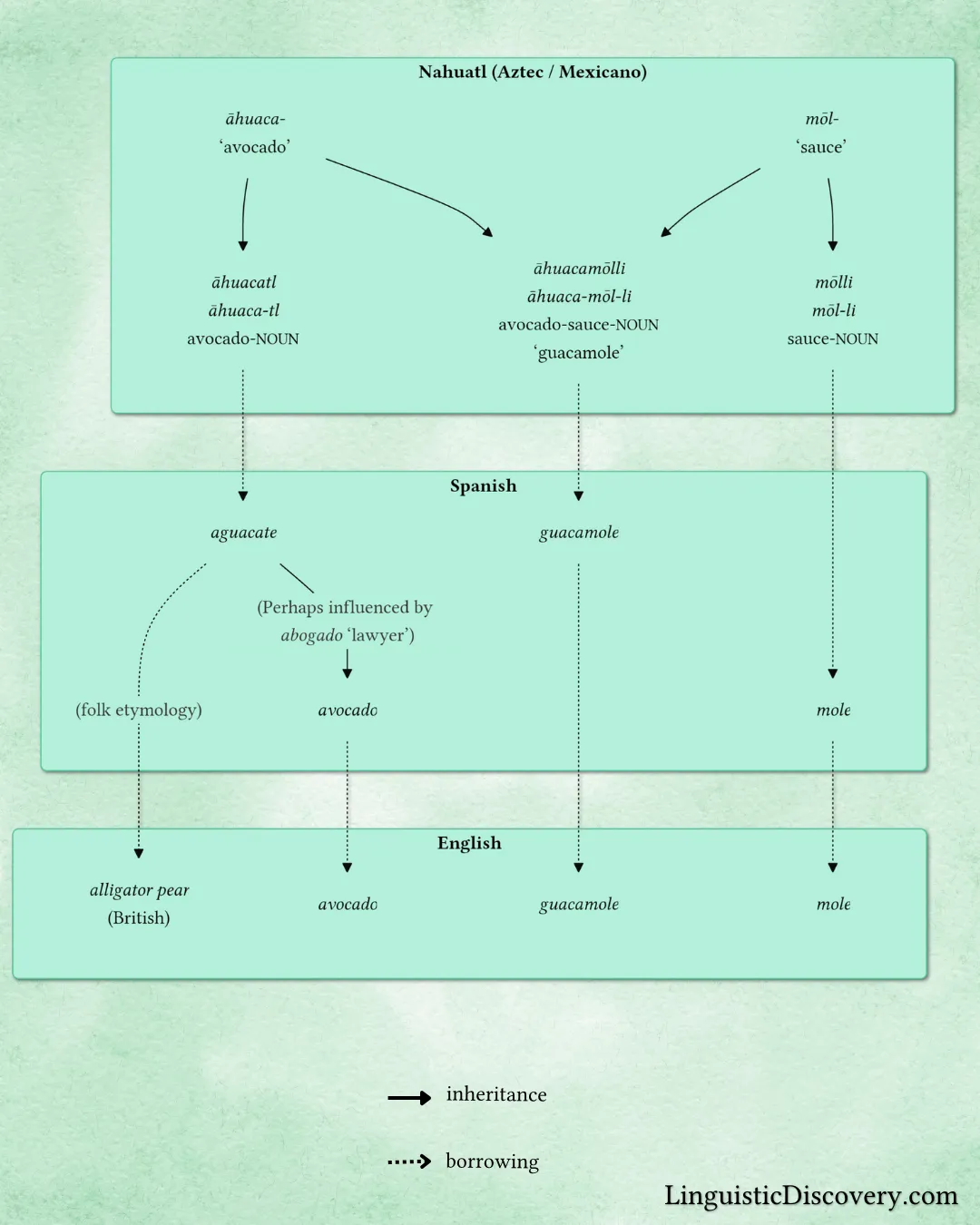
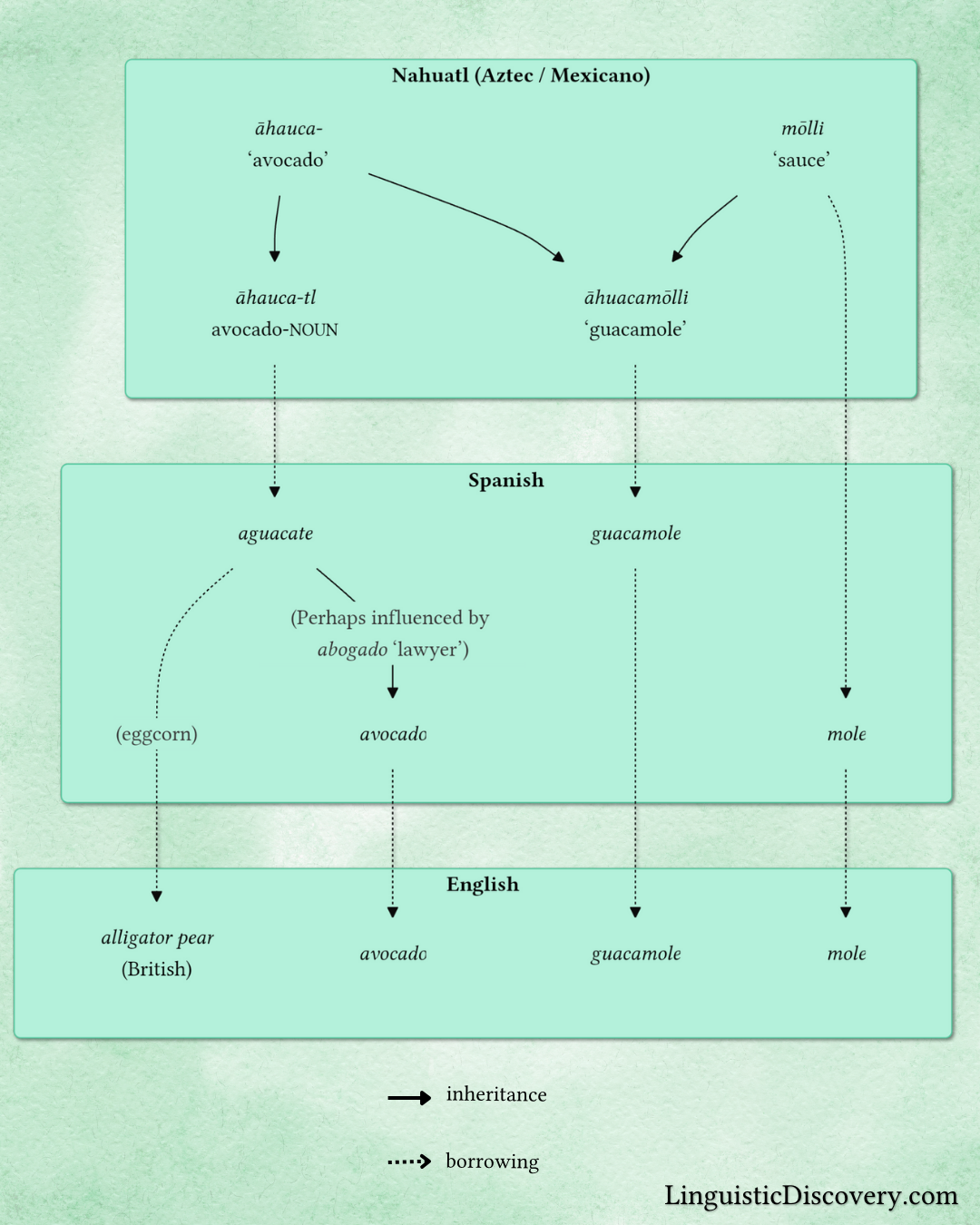
In my post on guacamole, I said that the word mōlli meant ‘sauce’, and while this is true, it obscures the fact that mōlli, like āhuacatl ‘avocado’, has a noun suffix at the end of it. The -tl suffix becomes -li after stems ending in /l/, so the base of mōlli is just mōl-.
I also had a small typo in the word āhuaca-.
Taking all this into consideration, I updated the etymological flowchart for ‘guacamole’, and the text of the accompanying article:
If you'd like to support Linguistic Discovery, purchasing through these links is a great way to do so! I greatly appreciate your support!
Check out my entire Amazon storefront here.