The writing on a recently-discovered tablet has linguists baffled, and GPT passes the Turing Test
Here’s what happened this week in language and linguistics.


Welcome to this week’s edition of Discovery Dispatch, a weekly roundup of the latest language-related news, research in linguistics, interesting reads from the week, and newest books and other media dealing with language and linguistics.
📢 Updates
Announcements and what’s new with me and Linguistic Discovery.

This week I attended one of YouTube’s Creator Collective events in Chicago, and had a blast meeting tons of other creators and talking shop about newsletters vs. videos, shortform vs. longform, how they’re monetizing, all the jazz. I came with a few new friends and very encouraged to continue my content creation journey! Thank you again to all of you who have supported me with either your precious time and attention, or your financial support along the way. It means a lot to have all of you reading and enjoying this newsletter.
So let’s dive in! Here’s what’s new in the world of linguistics this week:
📰 In the News
Language and linguistics in the news.

A stone tablet was discovered near Lake Bashplemi, Georgia in 2021, bearing an inscription in a script unknown to linguists, historians, and paleographers. There are 60 symbols total, 39 of which are unique. The tablet is dated from sometime in the 1st millennium BCE, which is around the same time that the Phoenician alphabet was spreading into Europe and becoming the Greek alphabet. This script, however, bears little resemblance to Phoenician.

🗞️ Current Linguistics
Recently published research in linguistics.
Inuit languages really do have more words for snow
I’ll have an entire post about this next week, but a new study looks at which areas of vocabulary different languages tend to have more words for, and it seems that Inuit languages really do have more words for snow:

A new corpus of spoken American English
One of the most important tools with which linguists study how people use language is a corpus (plural: corpora)—a dataset consisting of a collection of texts in a language. (A text in linguistics is any cohesive stretch of discourse, whether that be a written piece of text, a recorded conversation, a poem, a video of sign language users, a traditional oral narrative, etc.) Linguists use large corpora to study how grammatical patterns shift over time, or how certain linguistic features correlate with age, region, or other demographic factors.
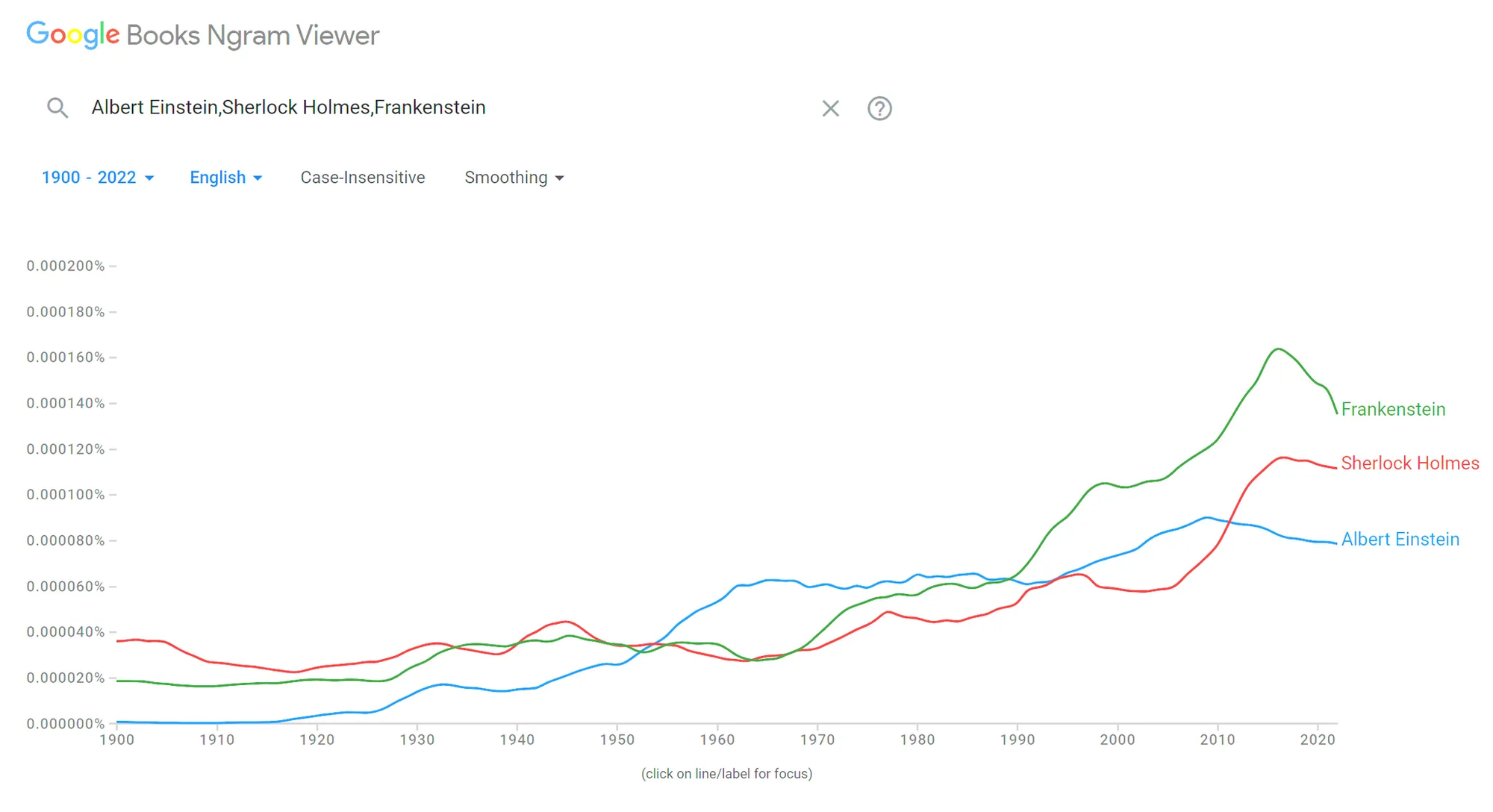
One of the most famous corpora is the Google Books corpus, which aims to be a corpus of the text of every book ever published. You can explore its data and examine trends using Google’s Ngram Viewer. More recently, large language models (LLMs) used in generative AI are being trained on absolutely massive corpora of billions upon billions of words. The Common Corpus, for example, consists of 500 billion words in various languages. Historically it had been impractical to create corpora of this size, so these mega-corpora are unlocking new research opportunities for linguists.
A major limitation of these corpora, however, is that they’re all text. Spoken corpora are much more difficult to compile and there are very few of them in existence. (And don’t even get me started on sign language corpora.) Researchers would have to recruit numerous participants, record them for hours, and spend an unseemly amount of time transcribing the audio. It often takes about 1 hour to transcribe just 1 minute of natural conversation, due to the fact that speech is riddled with restarts, overlap, hesitations, and talking over each other. Corpus linguists often transcribe at a fine level of detail too, indicating filler works like um and uh, intonational cues, length of pauses, and more—each of which provides helpful insights into cognition, grammar, and discourse. While modern speech recognition technology is making the task of transcribing audio significantly easier, it’s still a time-intensive task.
The onerous nature of creating spoken corpora is a shame, because speech is the natural modality for language. Natural conversation gives linguists the best insight into how people use language in real time, whereas writing is more artificial and planned, shackled to its own set of conventions that diverge drastically from how we speak.
So I was thrilled in 2023 when fellow linguistics communicator and now Ph.D.-holder Dr. Elizabeth Hanks (congrats Lizzy! 🎓🎉) told me about her work to create the largest-ever spoken corpus of American English, known as the Lancaster-Northern Arizona Corpus of Spoken American English (LANA-CASE). She asked if I would use my large social media presence to help recruit participants to be recorded for the corpus, and naturally I said yes, eager to support such a great research project. I put together an entire video series on corpus linguistics, which you can watch here:
- Corpus Linguistics, Part 1: Introduction
- Corpus Linguistics, Part 2: The Switchboard Corpus
- Corpus Linguistics, Part 3: My Top 10 Favorite English Corpora
- Corpus Linguistics, Part 4: Frequency & Cognitive Efficiency
Now, the data collection is finished, and we’re already beginning to see some early research that this new corpus has enabled! As reported in The Guardian, it seems that a growing number of Britishisms have made their way into American English in recent years. Interestingly, it’s Gen Z that’s the vanguard in adopting these words. You can see the complete top 10 in the article:

In any case, I’m proud to have played a tiny role in bringing this corpus to life, and am excited to see the interesting new research it will make possible!
GPT passes the Turing Test
A new study (not yet peer-reviewed) claims that GPT-4.5 passes the Turing Test 73% of the time. In a Turing Test, a human reads a transcript of a conversation between another human and a machine and tries to determine which of the conversationalists is the human and which is the machine. The machine passes if the human cannot reliably tell them apart.

Do our brains try to predict what’s coming next in a sentence? It may depend on the language you speak
Do our brains wait til the end of a sentence before trying to interpret it, or do they attempt to predict what’s coming next in the sentence? Previous neurological studies using English suggest that the brain waits for the sentence to end before interpreting everything, but a new study with Dutch suggests that Dutch speakers do in fact try to predict where the sentence is going. This means that different languages may foster different cognitive strategies for interpreting sentences. The reason for this may be that in Dutch sentences verbs come at the end, while in English sentences verbs are in the middle of the sentence. Since verbs are the pillar around which the rest of a clause is structured, it makes sense that Dutch speakers would be thinking ahead to what the verb might be.


The Pangloss Collection
A new collection of digital corpora of (mostly) endangered or underdocumented languages called The Pangloss Collection has just been released, along with an interface allowing users to listen to and read all the texts in the collection:


Interjections
Most people think of interjections like um, uh, oh, and uh-huh as meaningless filler words, but any linguist with some background in discourse and information flow knows that these are actually crucial parts of natural conversation, signaling to the speaker that you’re listening, or that you need to correct something you just said, or that you want the conversational floor next. They do a huge amount of social work in regulation conversation.
Knowable Magazine has an interview with Mark Dingemanse about his recent review article, “Interjections at the heart of language”, about just how important these types of words—what I’d call discourse markers—actually are.

📃 This Week’s Reads
Interesting articles I’ve come across this week.
Cognates with different meanings
Here’s a fun article from the Duolingo blog about why cognates can have the opposite or drastically different meanings across languages. I like that it acknowledges that there are several pathways by which this situation can come about. Here’s one illustration:


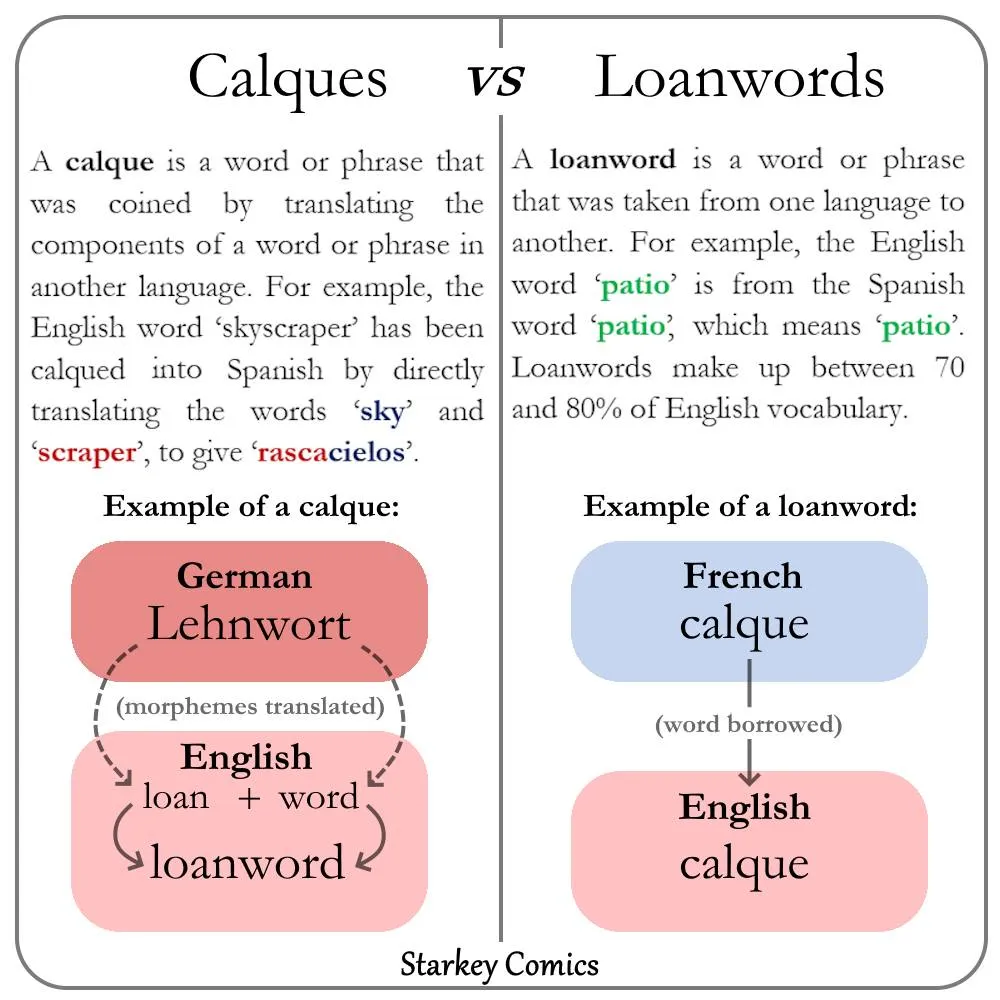
What’s the difference between a loan word and a loan translation (also called a calque)? Ryan Starkey of Starkey Comics has a great infographic with the answer:
Other Articles



📚 Books & Media
New (and old) books and media touching on language and linguistics.
I’m excited for this one, y’all! A new book about Proto-Indo-European (PIE) called, appropriately, Proto. It’s pretty cool that our understanding of PIE and the origins of the early Indo-European peoples has continued to evolve sufficiently in over the last two decades that we’re still getting updated looks at the latest science like this. The last popular look at Indo-European, The horse, the wheel, and language, is now almost 20 years old! So this new book is most welcome.


I should also mention a similar book coming out right around the same time, which I’ve mentioned in a previous issue of the digest: The Indo-Europeans rediscovered: How a scientific revolution is rewriting their story.

The King’s Letters is a South Korean historical drama about the invention of the Hangul writing system by Sejong the Great in 1443. Hangul is a unique writing system which combines phonetic units into syllable blocks, making it a combination of a featural alphabet and a syllabary.

I hope you enjoyed this week’s issue of Discovery Dispatch! Have a wonderful week!
~ Danny
If you'd like to support Linguistic Discovery, purchasing through these links is a great way to do so! I greatly appreciate your support!
Check out my entire Amazon storefront here.